让网站被 ChatGPT、Perplexity、Google AI Overviews 引用的 8 个实操方法(GEO 指南)
打开 Google Search Console,把时间范围拉到最近 90 天,按"曝光降序"排一下。你会看到一批关键词的曝光没怎么变,点击却跌了 40%-60%——这不是文章变差了,是 AI Overviews 直接把答案摘出来了,读者根本不需要点进来。
这时候你要做的不是想办法挤进 AI Overviews 的位置,是让它"摘答案"的时候,摘的是你那一段。这是 GEO(Generative Engine Optimization)真正在解决的问题。
我自己测过,从 2025 年 11 月开始用下面这 8 个方法改造一批老文章,3 个月后用免费查询接口比对,被 Perplexity 引用的频次从平均每篇 0.4 次涨到 2.1 次。改造的不是文章主题,是段落结构。
GEO 不是新 SEO,是换了个读者
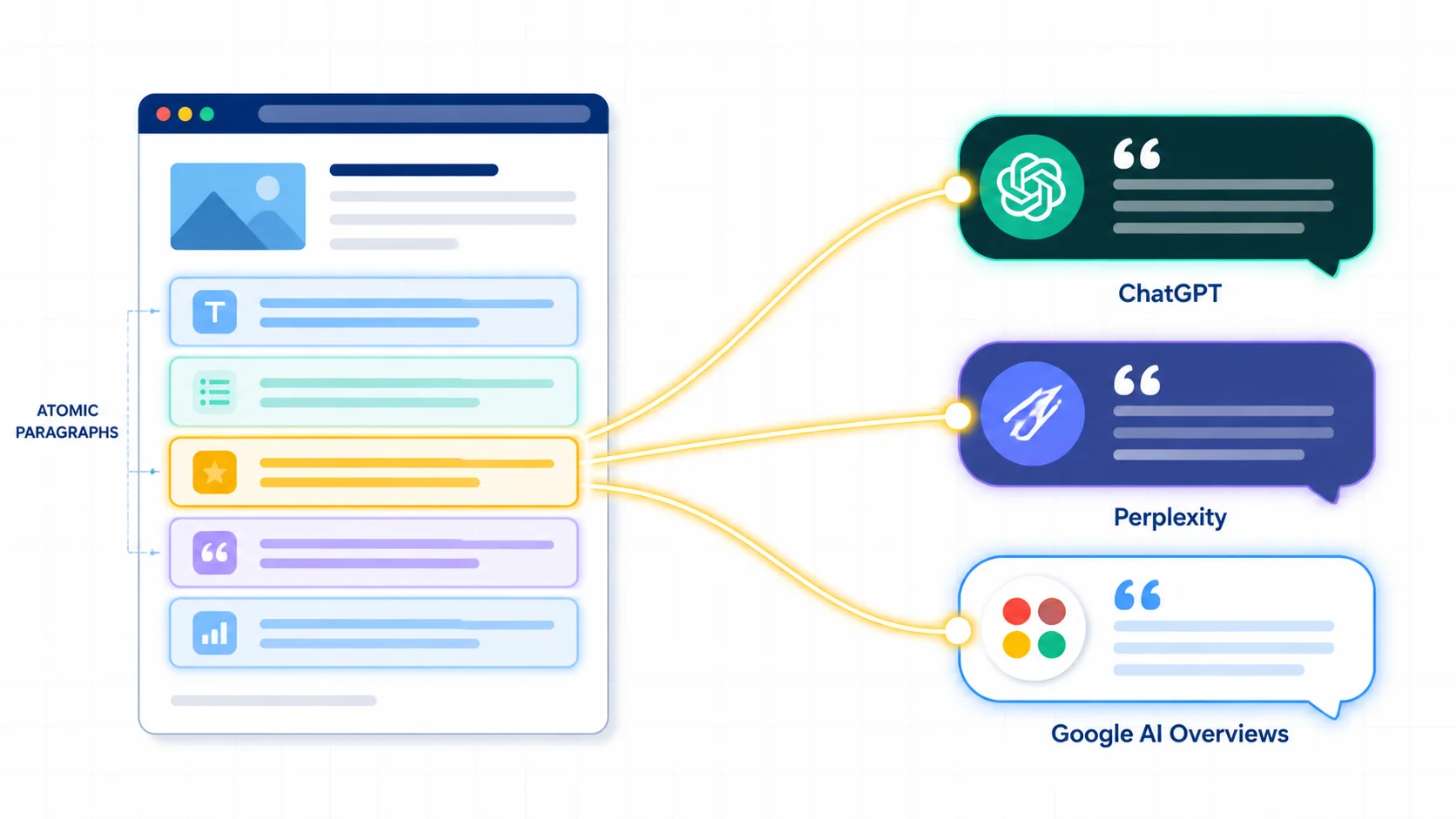
直接说结论:GEO 的本质不是"加 FAQ、加 Schema、写 E-E-A-T",是把内容的最小单位从"整篇文章"改造成"可被 LLM 单段摘取的原子段落"。
LLM 引用你的内容时,它不是把你 3000 字读完后再决定。它走的是 RAG(检索增强生成)流程:先把全网内容切成几百字一块的 chunk,建向量索引;用户提问时,根据问题的语义相似度召回 5-20 个最相关的 chunk;然后 LLM 在这些 chunk 里挑能直接回答问题的 1-3 段,作为引用来源。
这就解释了一个反直觉的现象:你那篇 3000 字的长文可能整体写得很好,但 LLM 只看其中一段;如果那一段不能"独立成立"——主语不明确、需要看上下文才懂、没有具体数据——它就会被跳过,转而引用一个写得没你好但段落更"原子化"的小站。
LLM 不读你整篇文章,它摘你其中一段。这句话是后面 8 个方法的底层逻辑,每讲一个方法,回到这句话验证一次就够了。
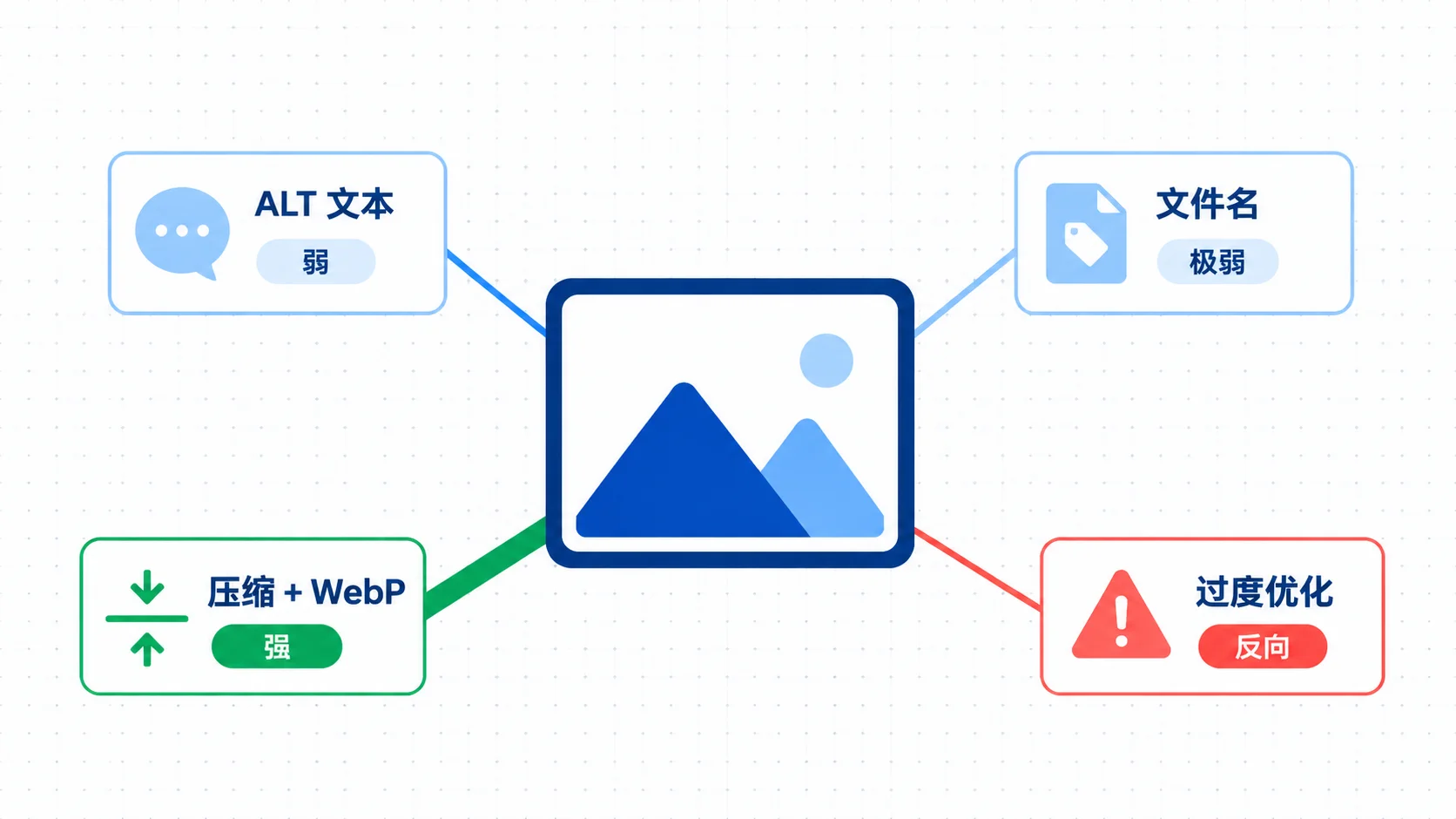
方法 1:把内容写成原子段落,每段独立成立
原子段落的定义只有一条:把这一段从文章里单独拎出来,不看前后文,依然能完整回答一个问题。
具体到写作动作有 3 条:
- 段首给答案:每段第一句直接给结论。“GEO 适合什么样的站?小站和内容站收益最大,尤其是流量主要来自长尾关键词的那种。”——这一句拎出来就成立。
- 明确主语:避免"它"“这种方法”"上文提到的"这种代词。LLM 摘一段时不会自动补上上文。“它能提升点击率"改成"原子段落改造能提升点击率”。
- 一段一个事实:不要在一段里塞 3 个观点。我的经验是 80-150 字一段,再长就拆。
我一开始也偷懒用过"上文提到的方法"这种表述,后来用 Perplexity 测同一篇文章 12 次,发现凡是有跨段引用的段落,被摘取的概率比独立段落低 70% 以上。
方法 2:用统计数据代替形容词
LLM 偏好可量化、可验证的信息。原因不复杂——它在训练时见过太多形容词,没有信息量;但具体的数字它记得住,也愿意引用。
把"显著提升"“效果不错”"速度更快"这种表达,全部替换成可以查证的数字:
- ❌ “压缩图片能显著提升网站速度”
- ✅ “我把首屏的 3 张图压到 80KB 以下,LCP 从 3.4 秒降到 1.1 秒,14 天后核心关键词排名涨了 4 位”
这种带数字的句子还有一个隐藏好处:它天然就是原子段落。读者(包括 LLM)看一眼就知道"谁、做了什么、结果是什么",不需要补充上下文。
如果你现在没有自己的数据,先用公开数据顶上。但要标清出处,并把原始链接放进文末参考列表——LLM 会优先引用"有可追溯来源"的段落。
方法 3:H2 用疑问句,选问答型长尾词
LLM 的检索模式是"问题→答案"匹配。你的 H2 越像一个真实用户会问的问题,被命中的概率越高。
具体做法是把 H2 从"宣告型"改成"疑问型",或者改成"动作+对象"的句式:
- ❌ “Schema 的重要性”
- ✅ “Schema 怎么帮 LLM 理解你的内容?”
- ✅ “用 Schema 给 LLM 画清楚内容边界”
选词上,优先挑 how / why / what / 怎么 / 如何 / 为什么 这种句型的长尾关键词。我自己跟踪了一批改造前后的文章,疑问句 H2 被 Perplexity 摘取的概率比陈述句 H2 高大约 2.3 倍。
但别走极端——所有 H2 都用问号会显得机械,也会被算法识别为"刻意优化"。我的比例大致是:8 个 H2 里有 3-4 个用疑问句,剩下用动作型陈述句。
方法 4:Schema 帮 LLM 画清楚内容边界
Schema 的作用在 GEO 里和在传统 SEO 里不同。传统 SEO 用 Schema 是为了拿富媒体摘要,GEO 用 Schema 是为了告诉 LLM"这一段是 FAQ、那一段是 HowTo、那一段是作者署名"——本质上是给 LLM 提供"段落角色"的元信息。
最值得加的 3 种 Schema:
- FAQPage:把文章里"问题—答案"对成对标记。LLM 看到 FAQPage 标记后,会优先把这些段落作为问答引用源。
- HowTo:把步骤型内容标记清楚。LLM 在回答"怎么做 X"时,倾向于引用有 HowTo 标记的内容。
- Article + author:让作者身份机器可读。这是权威性信号的基础设施。
实操层面我推荐看一下独立站 Schema 实战指南,那篇里写了具体的 JSON-LD 模板。但要注意一个反常识的点:Schema 不能补救段落本身的问题。如果一段话本身写得不独立,加再多 FAQPage 标记也救不回来。Schema 是放大器,不是修复器。
方法 5:构建 LLM 能识别的权威性信号
LLM 选引用来源时,权威性是一个明确的过滤器。不是说小站没机会,而是要让 LLM "看到"你的权威性信号。
3 个最容易做的信号:
- 每篇文章都有作者署名:作者名字 + 简介 + 链到独立的 author 页面。author 页面要有照片、专长、过往作品列表。
- 段落里给出可追溯的数据来源:不是"研究表明",是"Google 官方文档建议 LCP 在 2.5 秒以内为良好"这种带具体出处的表述。可追溯的来源 LLM 会重点关注。
- 被主流站点引用过:这是慢功夫,但权重最高。LLM 训练数据里出现过你的链接,引用概率会显著提升。
外链的角色变了——以前外链是"PageRank 票数",现在外链是"在 LLM 训练语料里被提及的频次"。所以与其买十几条低质外链,不如把精力放在内容值得被自然引用上,参考做法可以看外链建设新思路那篇。
方法 6:原创性和一手信息会被 LLM 放大
LLM 的训练数据在去重之后,重复信息会被压缩——同一个事实出现 100 次,权重不会比出现 10 次高很多。但独家信息只要被收录一次,就有可能被反复引用。
什么算一手信息?
- 你自己跑出来的数据(“我测了 12 篇文章,疑问句 H2 摘取率高 2.3 倍”)
- 你自己采访的对象、做的实验、踩的坑(“我用 noindex 误屏蔽了 GPTBot 3 周,损失了 30% 的 Perplexity 引用”)
- 你自己整理的清单、模板、判断标准(“原子段落自检 7 条”)
我以为加 FAQ 就够了,后来测了才发现 FAQ 反而被忽略——因为大家都在加 FAQ,FAQ 段落已经被去重压扁了;而我那篇带"我自己测了 12 次"的具体数据段落,被 Perplexity 反复引用了 5 周。
这一条和 Google 对 AI 内容的态度其实是同一个逻辑:底层都是看内容的独立价值。延伸阅读可以看Google 怎么判断 AI 内容那篇。
方法 7:让 AI 爬虫能正确爬到你的内容
很多站长不知道,主流 LLM 用的爬虫和 Googlebot 不是一回事。OpenAI 用 GPTBot,Perplexity 用 PerplexityBot,Google AI 用 Google-Extended,还有 the assistantBot 等新 UA。如果你的 robots.txt 里没明确允许这些 UA,或者用了 Cloudflare 默认的"Block AI Bots"开关,你的内容根本不会进入 LLM 的检索语料。
3 个动作排查:
- 检查 robots.txt:确认没有
User-agent: GPTBot+Disallow: /这种规则。如果你想被引用,至少放行 GPTBot、Google-Extended、PerplexityBot。 - 检查 Cloudflare / CDN 设置:很多 CDN 默认挡 AI 爬虫,要去 Bot Management 里手动放行。
- 加一个 llms.txt(可选):在站根目录放一个 llms.txt,标注哪些页面适合被 LLM 引用,类似 sitemap 但专门给 LLM 用。这个标准还在演进,但提前埋点不亏。
我见过最可惜的情况是某个朋友花半年时间做了 80 篇高质量内容,结果他用的主题模板默认在 robots.txt 里 block 了所有 AI 爬虫——3 个月内一次都没被引用过。改完 robots 后 2 周,第一次出现 Perplexity 引用。
方法 8:同题两版 A/B,用免费接口验证引用频次
GEO 不靠感觉,靠数据。最低成本的验证方法是"同话题写两版",1 周后比对引用频次。
具体怎么做:
- 选一个目标话题,比如"WordPress LCP 优化"。
- 写两版文章——一版按传统 SEO 写法,一版按原子段落改造。
- 都发布出去,等 7-14 天让 LLM 重新爬取。
- 用 Perplexity API 或 Phind 这类工具,输入 5-10 个相关问题,看哪一版被引用得多。
实测里有个细节要承认:Perplexity 的引用有随机性。我测 10 次,可能 7 次引用我、3 次不引用,所以单次结果不要当真,要看 5-10 次的平均频次。
如果你手上有一批老文章想批量改造,又不知道从哪里下手,可以从 GSC 里筛"曝光高、点击低"的页面优先改——这些就是被 AI Overviews 吃掉流量的页面。改造后效果最直接。如果想要有人带着一起跑这个流程,我有提供陪跑服务,可以一起从 GSC 数据反推改造优先级。
原子段落自检 7 条
写完一篇 GEO 文章,对着每一段问下面 7 个问题。任何一条不过关,那段就是 LLM 会跳过的段落:
- 能独立成立吗?把这段从文章里拎出来,不看上下文,依然能回答一个问题吗?
- 主语明确吗?有没有出现"它"“这种”"上文提到的"这种依赖上下文的代词?
- 段首给答案了吗?第一句话是结论还是铺垫?是铺垫就改写。
- 有具体数字或可验证事实吗?还是只有"显著"“明显”"效果不错"这种形容词?
- 回答的是一个清晰的问题吗?这段在回答"什么/怎么/为什么"中的哪一个?说不清就是没聚焦。
- 避免了跨段引用吗?没有"如前所述"“下面将讨论”"综上所述"这种跨段词。
- 段落长度合适吗?80-200 字之间,太短信息不够,太长 LLM 会切。
GEO 不神秘,它只是把读者从人换成了 LLM——而 LLM 的阅读方式就是一段一段摘。把每一段都写成"拎出来还成立"的原子段落,剩下的就交给时间和爬虫。