canonical、noindex、robots.txt 到底怎么选?先分清这 3 件事
很多小站一遇到收录问题,就会把 canonical、noindex 和 robots.txt 一起上。结果常常是页面没救回来,反而把本来能处理清楚的问题越弄越乱。
这三个工具最容易被误用的地方,不是语法,而是目标。它们处理的根本不是同一件事。如果你没先分清自己要解决什么问题,后面配得再完整也可能配错。
先分清:你要解决的是哪一种问题
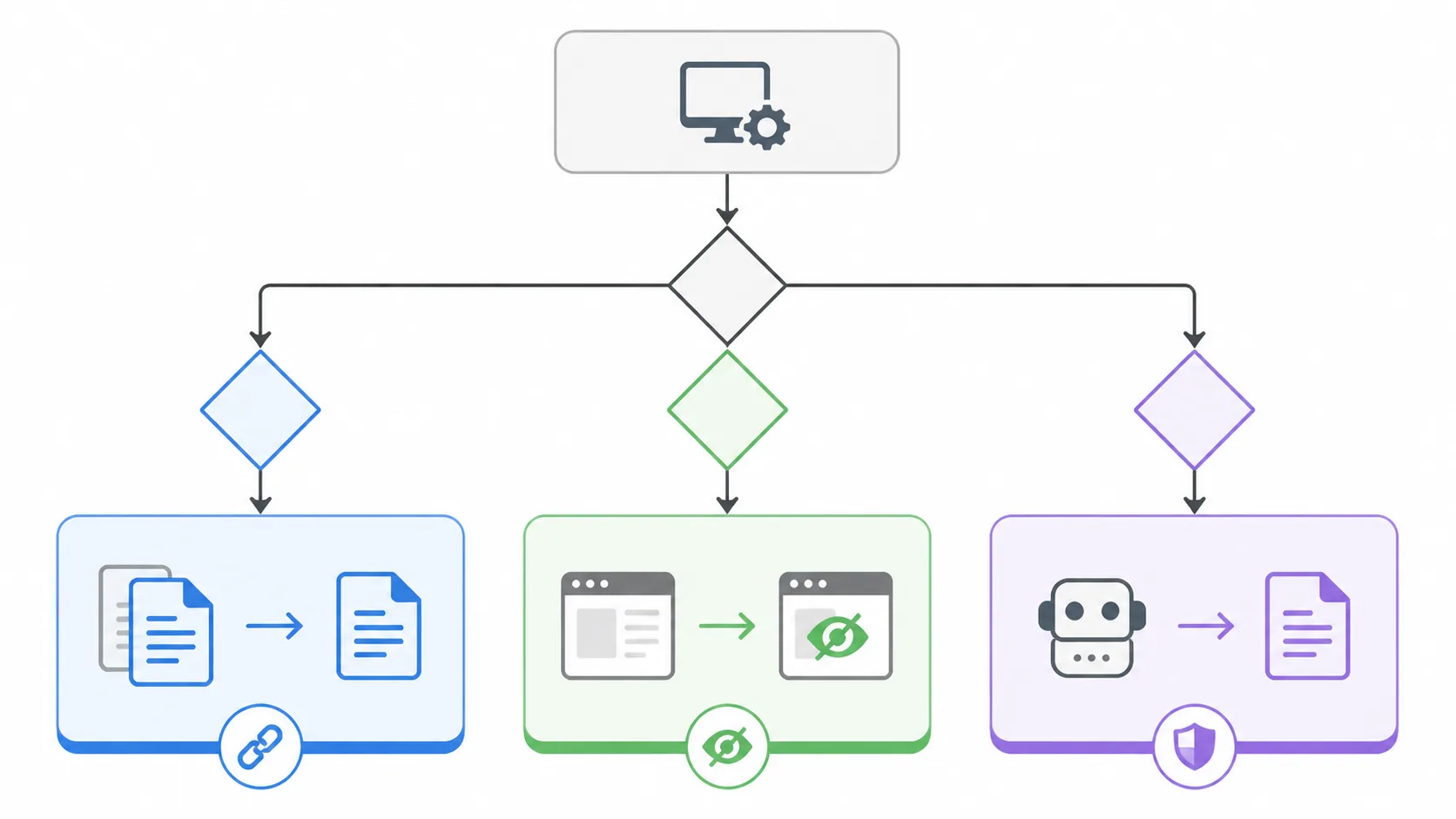
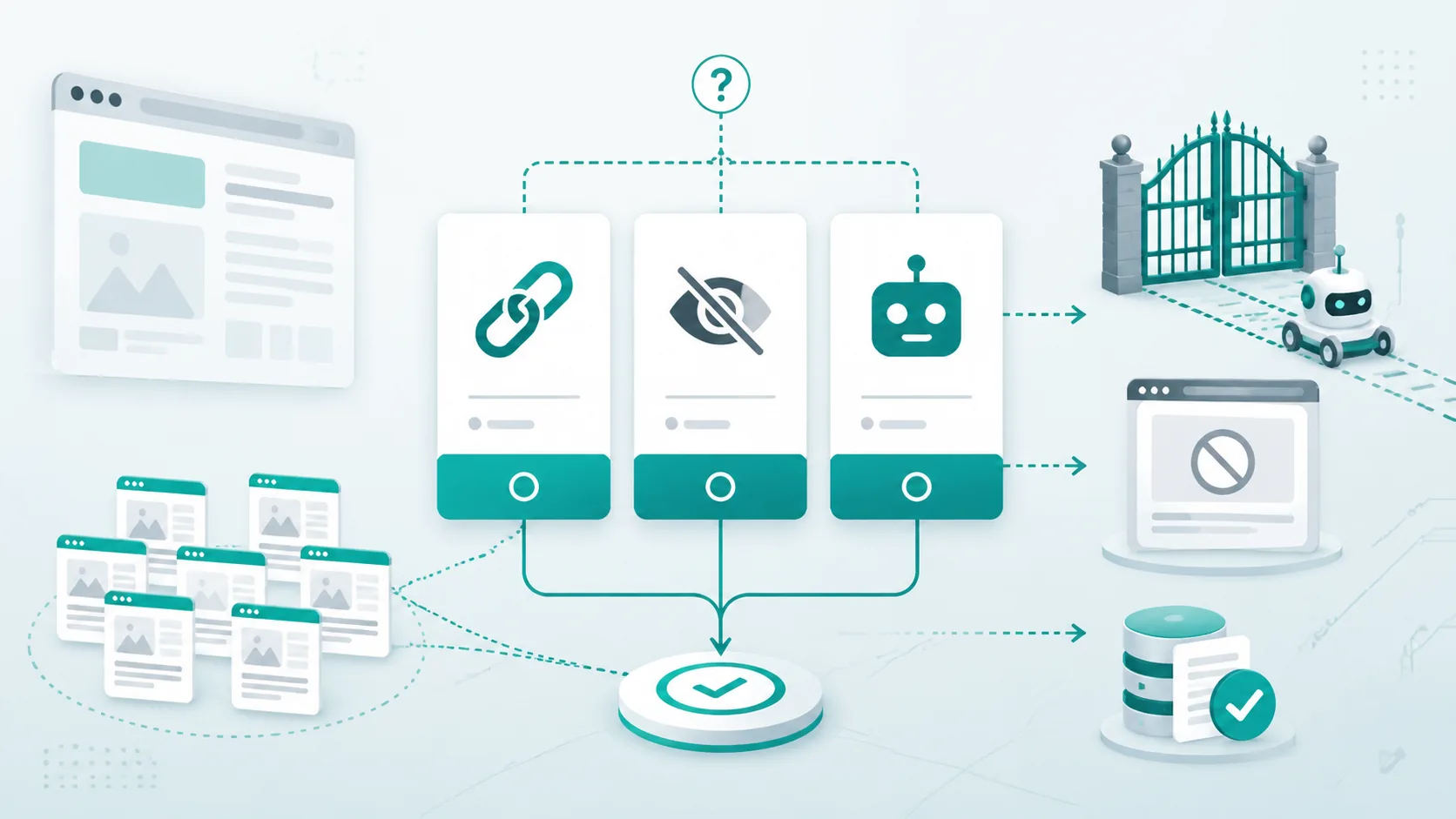
这三个工具对应三类完全不同的问题:
| 工具 | 它真正解决什么 | 最常见用途 |
|---|---|---|
| canonical | 重复版本怎么归并 | 告诉 Google 哪个 URL 才是主版本 |
| noindex | 哪些页面不想进索引 | 把页面从搜索结果里拿掉 |
| robots.txt | 哪些路径不想让爬虫抓 | 管理抓取入口和抓取范围 |
如果你面对的是重复版本页,却用 robots.txt 去挡;或者你想让页面不被索引,却只靠 robots.txt,不让 Google 看到 noindex,那问题就会开始串起来。
先问自己一句最实际的话:你到底是想“合并版本”、“禁止收录”,还是“减少抓取”?
这个问题答错,后面基本都会错。
遇到重复版本,先想 canonical,不要先想 robots.txt
如果几个 URL 内容基本一样,只是版本不同,比如:
- HTTP 和 HTTPS
- www 和非 www
- 带参数和不带参数
- 同一篇文章的多个可访问路径
这类问题更接近“选主版本”,不是“禁止抓取”。
这时 canonical 更合适,因为它是在告诉 Google:这些页面里,你应该把哪个当成主版本。
什么时候该优先用 canonical
下面这些情况通常先考虑 canonical:
- 页面内容主体相同,只是 URL 版本不同
- 你希望主页面继续被收录
- 你不想把重复页都硬删掉
- 你希望 Google 把信号尽量集中到一个版本
如果你用 robots.txt 去挡重复版本,Google 可能连页面内容都看不到,更谈不上判断主版本。你以为自己在“减少重复”,实际可能只是让 canonical 信号失效。
想让页面别出现在搜索结果里,优先想 noindex
如果你的目标不是归并版本,而是明确告诉 Google:这个页面不要进索引,那更接近 noindex。
常见场景包括:
- 站内搜索结果页
- 某些无独立搜索价值的标签页
- 临时活动页或测试页
- 薄内容的筛选页
- 你保留给用户看,但不想让它从 Google 落地的页面
这类页面的核心不是“重复版本”,而是“我不希望它出现在搜索结果里”。
noindex 最容易被误用的地方
最典型的误用是:一边给页面写 noindex,一边又在 robots.txt 里把它挡掉。
问题在于,如果 Google 被 robots.txt 挡住,很多情况下它根本看不到页面里的 noindex。你以为自己双保险,实际上可能是在互相打架。
所以想让 noindex 生效,先保证页面能被抓到。先让 Google 看见 noindex,再谈不收录。
robots.txt 主要是抓取控制,不是万能的“别收录”
robots.txt 更适合管理抓取边界,而不是直接当成“搜索结果屏蔽按钮”。
它的典型用途是:
- 避免爬虫抓某些无价值路径
- 减少参数页、后台路径、特定目录的抓取消耗
- 给站点抓取范围划边界
它确实会影响 Google 能不能访问某些 URL,但它不是最稳妥的“禁止进入 Google”方案。因为 URL 仍然可能被外部链接、站内引用或其他信号发现。
什么时候更适合用 robots.txt
| 场景 | 更适合用 robots.txt 吗 | 原因 |
|---|---|---|
| 后台路径或系统目录 | 是 | 本来就不需要被抓 |
| 大量无价值参数路径 | 是 | 先减少抓取浪费 |
| 测试目录 | 看情况 | 如果还可能被外链发现,要更谨慎 |
| 想把页面从搜索结果中移除 | 不是首选 | 这更像 noindex 的任务 |
| 重复版本归并 | 不是首选 | 这更像 canonical 的任务 |
如果你的目标是让页面别出现在搜索结果里,只靠 robots.txt 往往不够。这个点是小站最容易踩的坑。
小站最常见的 4 个实际场景
只讲概念容易抽象,放到场景里更清楚。
场景 1:同一篇内容有多个 URL 版本
比如 HTTP/HTTPS、www/non-www、参数版本都能打开。
优先动作:
- 先做规范跳转
- 页面上保留 canonical 指向主版本
这里重点是集中版本信号,不是单纯挡抓取。
场景 2:标签页很多,但大多数没有独立搜索价值
优先动作:
- 对没有明确搜索价值的标签页考虑 noindex
- 不要默认把所有标签页都放进索引
这里重点是索引控制,不是版本归并。
场景 3:大量筛选页和参数页让抓取很乱
优先动作:
- 先判断哪些参数页本来就不值得抓
- 对明显无价值的参数路径用 robots.txt 做抓取控制
这里重点是控制抓取范围。
场景 4:你给页面写了 noindex,但它还是状态混乱
优先动作:
- 先看页面是不是被 robots.txt 挡住
- 再看 Google 能不能真实访问这个页面
这类问题很多不是 noindex 没写,而是 Google 根本没机会看到它。
最容易出错的组合
下面这几种组合最容易把问题搞复杂:
- 想做 canonical,却先把重复页 robots 屏蔽
- 想 noindex 页面,却同时阻止抓取
- 不分场景,所有异常页都先写 robots.txt
- 把“减少抓取”和“禁止收录”当成同一件事
如果你之前已经在 GSC 收录异常排查 里看到过灰色状态,这篇可以当成更细的一层工具选择:不是再解释为什么没收录,而是解释遇到不同问题时应该用哪把工具。
一个够用的决策顺序
小站实际操作时,可以按这个顺序判断:
- 这是重复版本问题吗?
- 如果是,先考虑 canonical
- 这页是保留给用户看,但不想进搜索吗?
- 如果是,优先考虑 noindex
- 这是抓取浪费问题吗?
- 如果是,再考虑 robots.txt
这个顺序的核心是:先想目标,再选工具。不要从工具名字出发。
结论
canonical、noindex 和 robots.txt 最容易被混用,是因为它们都和收录有关,但它们并不解决同一个问题。canonical 处理主版本,noindex 控制是否进入索引,robots.txt 控制能不能抓。
小站技术 SEO 真正该做的,不是把三者堆在一起,而是先分清你要解决的是重复、索引还是抓取。目标清楚了,工具选择反而很简单。